
Note: The opinions expressed within this post represent only the views of the author and not any person or organization.
As a Presidential Innovation Fellow, I’ve had the pleasure of working with some of the most brilliant, forward-thinking minds in the workforce. During the past few months, my work has focused more specifically on skills and training arenas, and one thing that struck me is that the skills ecosystem is the entire economy. Its success will lead to a thriving and solid economic base.
It’s one thing to make this realization; translating this realization into action is quite another. The problem of understanding the skills space and iterating on it to produce the system that its users — i.e. job seekers, employers, colleges, workforce investment boards, etc. — need is a very important one. Related, it’s one that will require the participation of many more people.
Before we delve too deeply into this issue, let’s cover a few basics. The de facto source of skills information, both inside and outside the federal government, is O*NET - the Occupational Information Network.
What is O*NET?
O*NET is a data collection program that populates and maintains a current database of the detailed characteristics of workers, occupations, and skills.
Currently, O*NET contains information on 974 detailed occupations. This information is gathered from a sample of national surveys of businesses and workers. For each of these 974 occupations, O*NET collects data on 250 occupational descriptors.
As you might guess, O*NET is intended to be a definitive source for persistent occupation data — in other words, data on stable occupations that have existed (and will continue to exist) in the medium term. Examples of some such occupations include firefighter, teacher, and lawyer, to name a few.
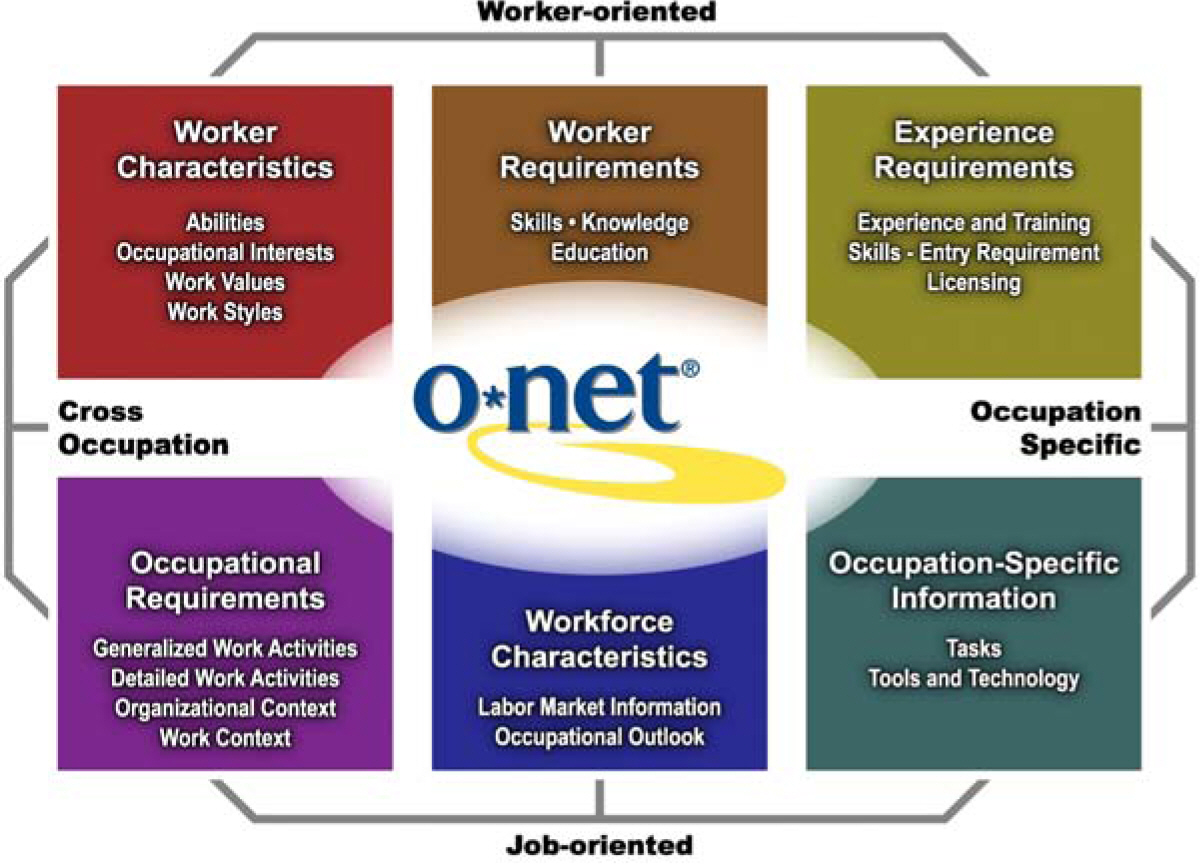
Fig. 1: O*NET content model
O*NET supersedes the U.S. Department of Labor’s (DOL’s) Dictionary of Occupational Titles (DOT) and provides additional occupational requirements not available in the DOT. The DOT is no longer supported by DOL.
O*NET uses an occupational taxonomy, the O*NET-SOC, which is based on the 2010 version of the Standard Occupational Classification (SOC) mandated by Office of Management and Budget (OMB) for use by all federal agencies collecting occupational and labor market information (LMI).
What Is O*NET good at?
O*NET is the bedrock of occupational data — some users think of it as a one-stop shop for data on occupations that have existed (and will exist) for some time. In a phrase, it is the gold standard of data on occupational skills – data upon which laws are created and an economic ecosystem can be built.
How often does O*NET data get updated?
The O*NET data set gets updated once a year. Currently, this is the fastest that comprehensive, consistent, representative, user-centered data, which complies with OMB’s Information Quality Guidelines and data collection requirements, can be gathered and processed.
How does O*NET collect its data, anyway?
Data collection operations are conducted by RTI International at its Operations Center in Raleigh, North Carolina, and at its Survey Support Department, also located in Raleigh.
O*NET uses a two-stage sample — first businesses in industries that employ the type of worker are sampled and contacted — then when it is confirmed that they employ those workers and will participate — a random sample of their workers in the occupation receive the O*NET survey form and respond directly.
When necessary, this method may be supplemented with a sample selected from additional sources, such as professional and trade association membership lists, resulting in a dual-frame approach.
An alternative method, based on sampling from lists of identified occupation experts, is used for occupations for which the primary method is inefficient. This method is reserved for selected occupations, such as those with small employment scattered among many industries and those for which no employment data currently exist on which to base a sample, such as new and emerging occupations.
At the current funding level $6.2 million for PY 14 the O*NET grantee updates slightly more than 100 occupations per year with new survey data.
Why use sampling and surveys?
O*NET currently uses sampling and surveys to gather its massive amounts of data because these are the best techniques that also comply with the OMB Information Quality Guidelines (IQG). These guidelines identify procedures for ensuring and maximizing the quality, objectivity, utility, and integrity of Federal information before that information is distributed. OMB defines objectivity as a measure of whether disseminated information is accurate, reliable, and unbiased. Additionally, this information has to be presented in an accurate, complete manner, and it’s subject to quality control or other review measures.
O*NET was designed specifically to address OMB IQG, including OMB information collection request standards, and to correct some fairly serious limitations in the Dictionary of Occupational Titles.
What are other foundational principles of O*NET?
In addition to serving as a comprehensive database of occupational data and promoting the integrity of said data, O*NET upholds several other principles. These include the following:
- Comprehensiveness — O*NET data covers the entire economy, offering information from all occupations in the labor market.
- Consistency — O*NET describes each and every occupation consistently, which helps facilitate analysis of skill transferability.
- Broadly representative — O*NET’s data is sampled from across the labor market, the nation, and employing industries.
- User-centered — Incumbent workers or occupational experts are the primary respondents to O*NET’s surveys.
Why does O*NET only contain survey-based data?
Using survey-based data enables O*NET to have comprehensive coverage, be very representative, enable the data to be validated and cleaned relatively easily, enable the statistical calculation of margin of variance or error, and to meet the OMB data collection requirements. Even though this type of data tends to be higher cost than other data types, survey-based data results in average or mean values (by design).
What about other types of data?
There are two other primary types of data that could be included in the O*NET data set — transactional data and crowdsourced data.
Transactional data tends to be privately owned and have a potential for response bias. Currently, occupational and industry coverage is limited, e.g. in certain industries, online job postings are the norm and in others, it is not. Also, the use of online job postings vary with the size of the firm — smaller employers are less likely to post job openings online. Finally, many postings don’t specify the information desired by O*NET curators.
Crowdsourced data tends to the least representative of the set, has the greatest potential for response bias, can be very difficult to validate independently and can easily capture leading or emerging variations.
Both transactional and crowdsourced data would require significant investments in curation and management for them to satisfy the OMB Information Quality Guidelines and the O*NET Foundational Principles, which are intended to fix the problems with the DOT.
What is the biggest misconception about O*NET?
“Why isn’t Python an O*NET Skill?”, “Why is Active Listening an O*NET Skill?”, “Why are O*NET Skills so broad and generic?”
Members of the O*NET team hear these and similar questions with relative frequency. The above questions echo one primary misconception about O*NET, which is O*NET Skills are too general.
What many users don’t realize is that O*NET skills — for example, active learning and programming — refer to cross-cutting competencies fundamental to a given occupation. More specific descriptors (such as systems, platforms, and other job-specific tools) are captured under the Tools & Technology section of an occupational profile.
O*NET Skills, as perceived by most of the public, are actually a combination of what we describe in the Tools & Technology, Detailed Work Activity, Abilities, Tasks, Skills and Knowledge sections of an O*NET occupational profile. In short, Skills are just the tip of the occupational iceberg.
What are the issues that you hear voiced most about O*NET?
The current set of concerns with the O*NET program include:
-
Frequency – updating the O*NET database once a year is simply not acceptable in an era where the Internet is accelerating change every one to three months.
-
Relevance and Recency – the exclusion of current professions and fields from the O*NET database reduces its usefulness to me.
The update frequency is in large part a function of the data collection and quality constraints on O*NET. A possible solution is the creation of skills technology pipeline that can be incubated outside of O*NET. Once proven, these technologies may be evaluated for transition into the program.
Official datasets from the Federal government are constructed to be a stable, steady base upon which more transitional elements can exist. This stability is designed to ensure that the American people see a consistent face when dealing with their government.
For this reason, jobs that appear and disappear within the space of months or a few years, like Chief Fun Officer or Growth Hacker, are not immediately included in the O*NET database. Only occupations that have stood the test of time should be included in an authoritative source; upon which regulatory decisions are made.
How do we solve these issues?
A public-private partnership that produces a Skills Market Platform (SMP) (Fig. 2), which is an open, dynamic, growing, standards-based, public-facing platform for skills data.
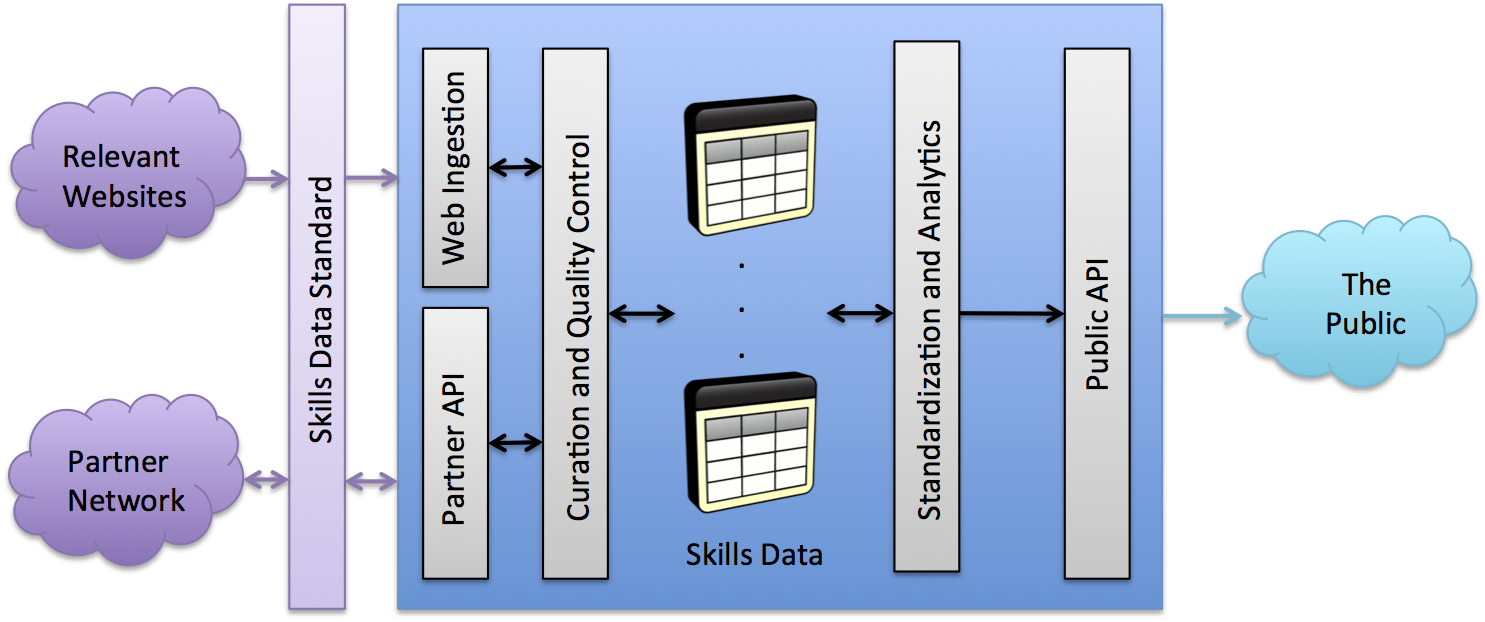
Fig. 2: reference architecture for a Skills Market Platform (SMP)
The SMP should be run by a nonprofit that will handle the data curation, quality control, analytics and the public application programming interface (API).
It is assumed that all contributions to the SMP will be tagged with skills from the Skills Data Standard (SDS) – a standard that is currently being developed.
Employers can provide tagged job descriptions. Job seekers can tag their resumes using the SDS taxonomy or import their skills using OpenBadges (or similar) framework. Colleges can tag their courses with the imbued skills. Certification bodies can tag their programs with the delivered skills.
The core idea behind the SMP is to conceptualize, design, and build a national skills platform — which would be populated with data over time. Federal government information and existing taxonomies would provide the foundational structure and bring data from O*NET, from the Bureau of Labor Statistics, Commerce data from the Census, the American Community Survey, and the Longitudinal Employer-Household Dynamics data sets. Other partners would be able to upload additional data—such as a college course catalog, or the competencies imparted by a specific certification—or data mined from tagged job postings or resumes.
Local areas where community colleges and the workforce system are already collaborating closely with business — such that curriculum is closely tied to employer skills demand could upload information on the linkages between employer skill demand and specific competency-based education modules. Such early adopters would be able to demonstrate the utility of such a platform and build a community to further build out and participate in the SMP.
The ultimate goal is for the Federal government to facilitate the creation of the innovation platform for skills; enabling any American to freely and openly leverage a common language and knowledge base.
What needs to be done
The Skills Market Platform relies on an existing:
-
Skills Data Standard (SDS) - that defines the basic element of the system - a Universal Skill Unit (USU) - and its components and dependencies.
-
Skills Network Protocol (SNP) - that enables skill units and their underlying data to operate dynamically across networks and to interact with other data systems such as O*NET and commercial systems that might be used by employers.
-
Skills Innovation Layer (SIL) that allows experimentation with the SDS and SNP and enables innovations on top of it.
Call to action
Ever wondered what skills a particular certification course gives you? Ever debated the true skills details of a job description? Are you passionate about skills, competencies, abilities and knowledge? Contribute to this effort. Spend some time helping us create the Skills Data Standard. Donate some programming and design cycles to implementing the Skills Network Protocol and or the Skills Innovation Layer. Help change the world as we know it.
